Construire et optimiser un système de recommandation de films
Posté le 03. Novembre 2022 • 2 minutes • 286 mots
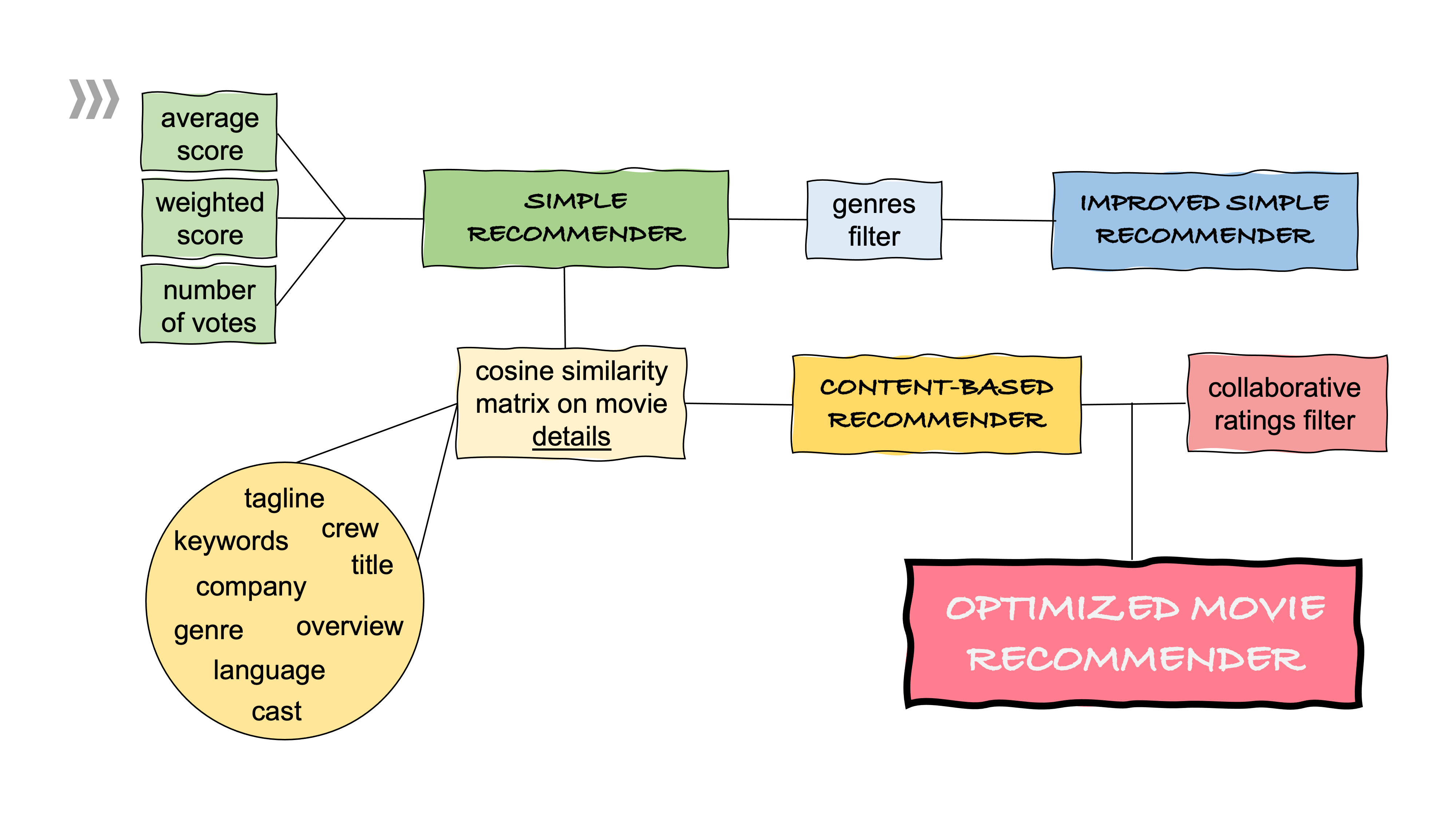
L’objectif de ce projet est de construire un système de recommandation de films, en utilisant les dernières données grattées à partir de GroupLens et The Movie Database. Les données de GroupLens ont été mises à jour pour la dernière fois le 26 septembre 2018. Le jeu de données comprend les données de 283228 utilisateurs entre le 09 janvier 1995 et le 26 septembre 2018, et contient 27 753 444 évaluations et 1 108 997 applications de tags sur 58 098 films.
Collection de données
Les identifiants et les informations des films ont été extraits de GroupLens et utilisés pour extraire des données sur les films de The Movie Database à l’aide d’une API. Les données extraites contiennent des informations sur le nom, les acteurs, l’équipe, l’année de sortie, la classification adulte, l’affiche, les recettes et la durée du film, entre autres. Après le nettoyage des données et l’ingénierie des fonctionnalités, l’ensemble de données comprend 18 champs décrits ci-dessous :
| Variable | Description |
|---|---|
| id | ID du film dans le TMDb |
| year | L’année de sortie du film |
| title | Le titre du film en anglais |
| runtime | Durée du film en minutes |
| collection | Nom de la collection, s’il y a lieu |
| genres | Genres de films |
| tagline | Le slogan du film |
| overview | Aperçu de l’intrigue |
| cast | Noms des 5 premiers membres du casting |
| director | Nom du directeur du film |
| producer | Nom du (des) producteur(s) du film |
| keywords | Mots clés du film |
| adult | Classification du film pour les adultes (bool) |
| prod_comp | Nom de la/des société(s) de production |
| languages | Langues utilisées dans le film |
| popularity | La popularité du film sur TMDb |
| vote_count | Nombre d’utilisateurs ayant évalué le film sur TMDb |
| vote_avg | Note moyenne du film sur TMDb |
Optimisation du flux de travail