Le coût de l'assurance-maladie
Posté le 12. Décembre 2022 • 2 minutes • 257 mots
L’objectif de ce projet est de prédire le coût de l’assurance maladie encouru par les individus en fonction de leur âge, de leur sexe, de leur IMC, du nombre d’enfants, de leurs habitudes tabagiques et de leur localisation. L’ensemble de données a été exporté de Kaggle et conservé par l’utilisateur Miri Choi.
| Variable | Description |
|---|---|
| age | Âge du bénéficiaire principal |
| sex | Sexe du contractant d’assurance, femme, homme |
| bmi | Indice de masse corporelle, permettant de comprendre le corps, les poids qui sont relativement élevés ou faibles par rapport à la taille, indice objectif du poids corporel (kg / m ^ 2) utilisant le rapport de la taille au poids, idéalement 18,5 à 24,9 |
| children | Nombre d’enfants couverts par l’assurance maladie / Nombre de personnes à charge |
| smoker | Fumeurs |
| region | Zone de résidence du bénéficiaire aux États-Unis, nord-est, sud-est, sud-ouest, nord-ouest |
| charges | Frais médicaux individuels facturés par l’assurance maladie |
Plan du projet
- Ingestion et nettoyage des données
- Ingénierie des caractéristiques
- Évaluation des modèles de régression linéaire
- Résumé
Résumé du projet
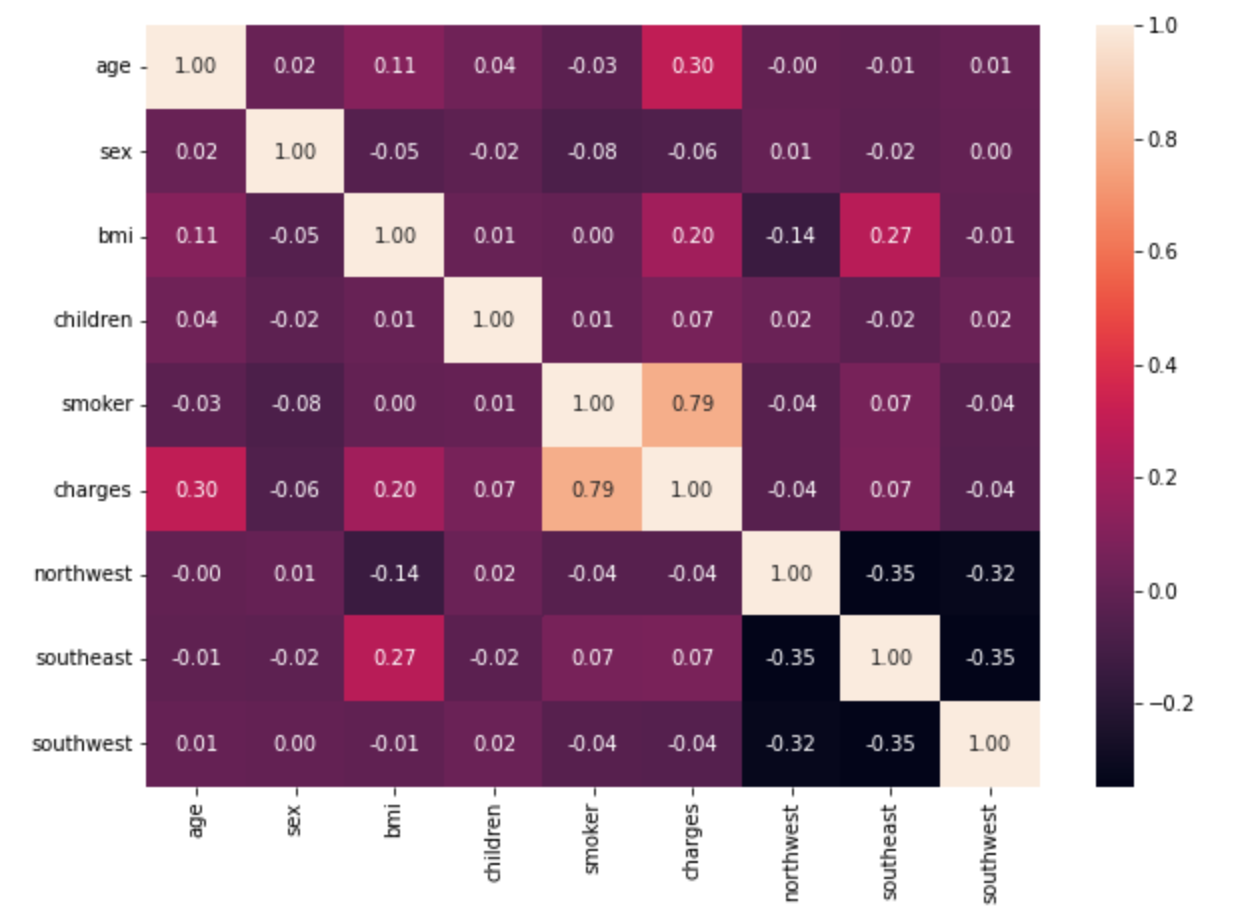
Après l’ingestion et le nettoyage des données, les variables catégorielles ont été encodées à l’aide de valeurs numériques. Une analyse exploratoire des données a également été menée, afin de mieux comprendre l’ensemble des données.
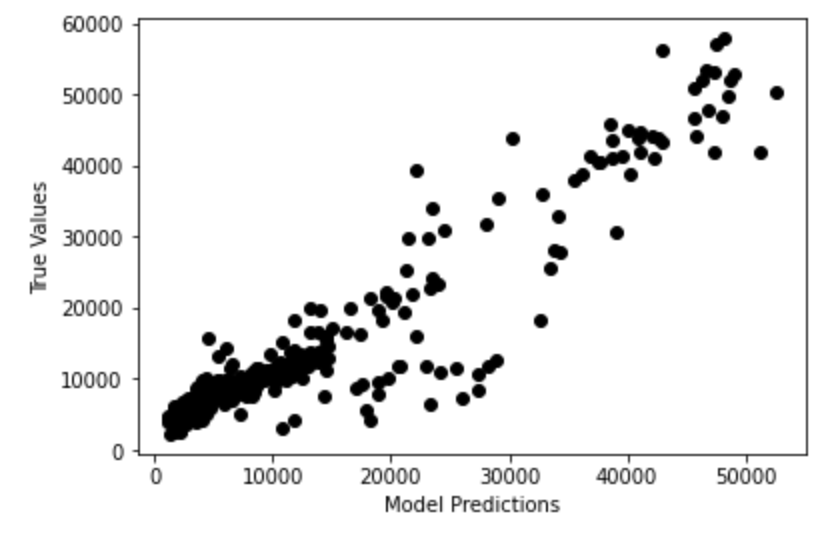
Ensuite, un modèle de régression linéaire a été utilisé pour prédire les primes de soins de santé en fonction des caractéristiques pertinentes. Le modèle de régression linéaire a donné des résultats modérément bons (précision ~75%), l’utilisation d’un réseau neuronal artificiel (entraîné pendant 100 époques) a donné de meilleurs résultats avec une précision d’environ 85%.