Prévision de l'attrition chez les travailleurs de la Santé Publique
Posté le 20. Décembre 2022 • 2 minutes • 389 mots
Embaucher et former des employés est un processus coûteux qui nécessite du capital, du temps et des compétences. En moyenne, les entreprises perdent 1 à 2,5 % de leur chiffre d’affaires total en raison du temps nécessaire à la mise à niveau d’un nouvel employé. En outre, les entreprises dépensent 15 à 20 % du salaire d’un employé pour recruter un nouveau candidat. Par conséquent, il pourrait être avantageux pour les entreprises de prévoir quels employés sont susceptibles de démissionner en fonction de certains facteurs et de prendre des mesures préventives si possible.
Pour en savoir plus, cliquez ici
Résumé
L’objectif de ce projet était de s’attaquer à l’attrition des employés dans le secteur de la santé. En particulier, je voulais répondre à deux questions :
- Quels employés sont susceptibles de partir?
- Peut-on prédire de manière préventive l’attrition des employés?
Pour répondre à ces questions, j’ai décidé de former deux modèles d’apprentissage automatique - un modèle non supervisé (regroupement) pour mieux comprendre les différentes classes d’employés licenciés et un modèle supervisé (classification) pour prédire l’attrition des employés.
Jeu des données
Les données
explorés dans ce projet a été créé par l’utilisateur Kaggle JohnM. Il contient 35 champs et 1676 enregistrements d’employés. Il contient des informations démographiques sur les travailleurs de la santé, notamment leur sexe, leur statut marital et la distance qui les sépare de leur lieu de travail. Elle contient également la rémunération de chaque employé, les évaluations de différents aspects de leur environnement de travail.
Conclusions: Clustering Analysis
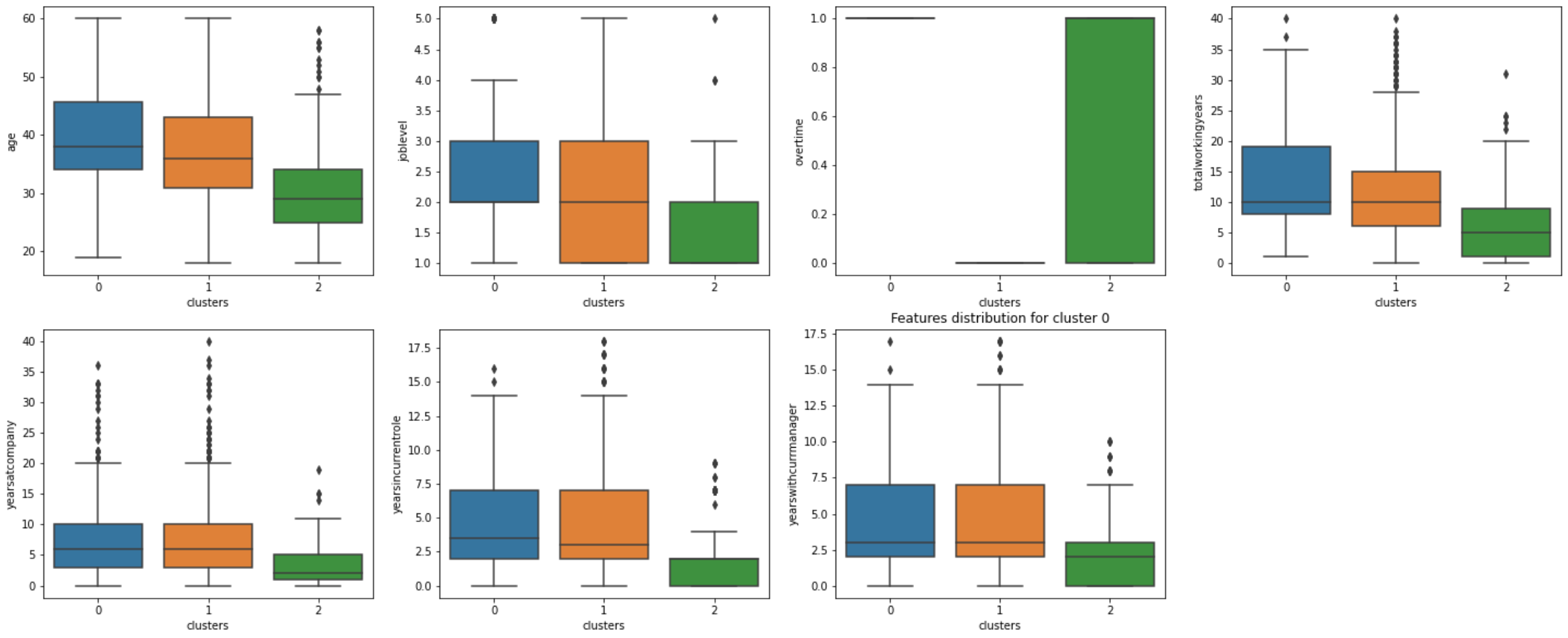
En général, les employés qui ont tendance à quitter leur lieu de travail (groupe 2) sont plus jeunes (âge moyen = 30 ans), débutants et ne travaillent pas depuis longtemps (à l’hôpital ou ailleurs). Il est intéressant de noter que les heures supplémentaires n’ont pas joué un rôle important dans l’attrition, car la distribution du personnel dans le cluster est également répartie pour cette caractéristique.
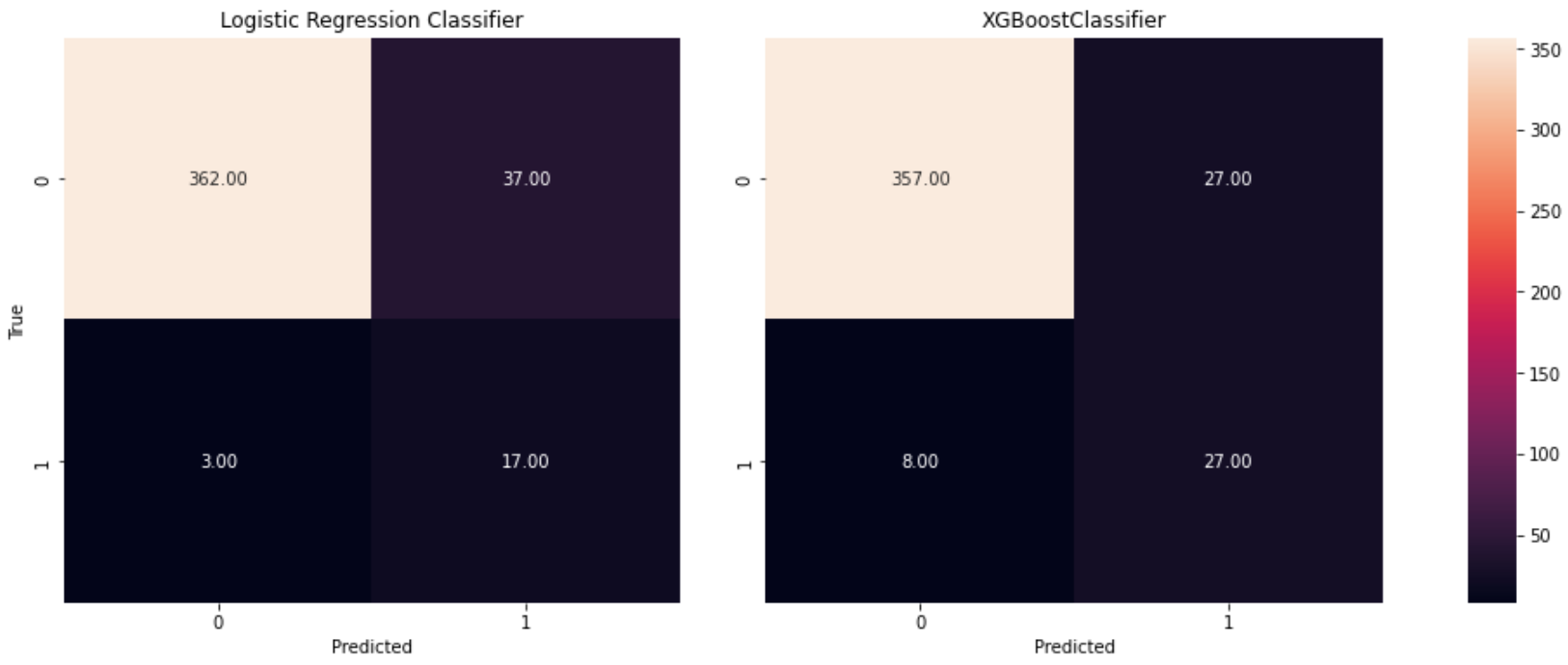
Conclusions : Prédiction de l’attrition des employés
Deux modèles de régression ont été formés et évalués dans le cadre de ce projet : un classificateur de régression logistique et un classificateur XGBoost. Dans l’ensemble, les deux classificateurs ont donné de bons résultats, avec des scores de précision élevés (~90%). Néanmoins, le modèle XGBoost avait un meilleur rappel que le modèle de régression logistique, ce qui en fait l’option recommandée pour cette analyse.